
教你用IDA
还得是你 IDA
# 教你用 IDA
还在为 IDA 反编译出的代码一坨答辩而烦恼吗,还在为玩不明白 IDA 而遭人鄙夷吗,那么今天来点大家想看的东西,只需 C 语言数据结构基础,教你调教出汉语言文学专业的妹妹都能看懂的代码
# IDA 迷惑代码大赏
- 首先介绍一下 IDA 里常见的屎,我们打开一道某城杯的 ez_linklist 题目
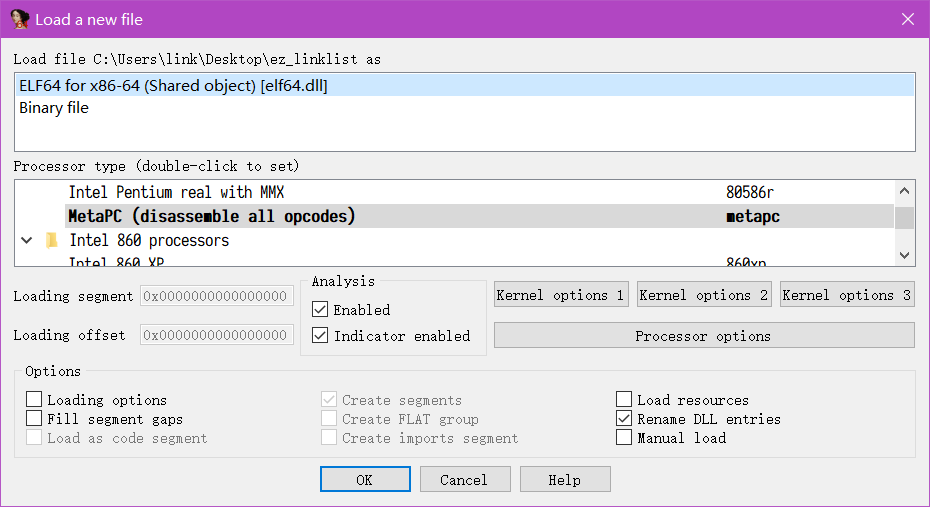
- 点下 ok 找到 main 函数,映入眼帘就是一坨很经典的屎,
switch跳转表识别错误,属于是史里比较正常的一坨,这还不是很影响分析的部分

- 看一眼侧边栏,很经典的
拿掉自定义的函数名,那么本程序的数据结构肯定也就没有了
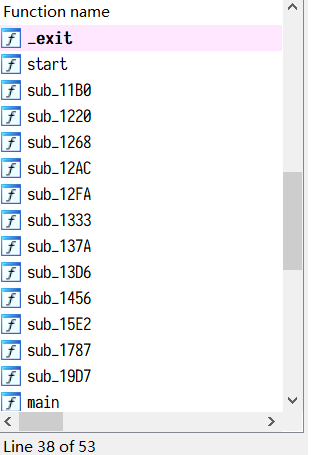
- 我们向上逐个点进去看一眼,更是个寄吧,
各种解引用强转写的和一把米诺一样(恼),看起来就像是精神状态欠佳的人写出来的代码

- 接下来点进 puts 下面的函数,
call了不知道个什么b玩意,鉴定为纯纯的纯纯

- 这里面更是直接
见红
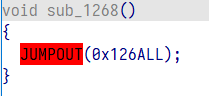
如果你也遇到了如上情况,别急,立刻点击右上角叉叉放弃本题(不是),请接着往下看
# C 语言变量复习
正经复习环节,众所周知 c 语言有很多基本变量类型,比如 int char 也有数组等等
有下面的变量
int a;
int b[10];a 便是 int 类型的变量,b 是一个 int 数组,他们都是我们的常见类型
-
其中 a 实际上指向了一块地址所指的值,其 int 表示将 a 地址中的东西以 int 类型来解析出来,所以我们直接输出 a 可以输出
a 存放的值 -
而 b 指向了一块地址,其 int 表示 将 b 里面的数据用 int 类型解析出来,但是直接输出 b 不能输出
b 存放的值,而是输出了b 的地址,因为b本身就是一个地址,因此需要加上 b 后面的下标也就是 b [x] , 才能输出b 对应位置所存放的值,对 b 取索引的操作也同样是对 b 以 int 类型解引用
所以之后在单独使用变量时由于前面的声明:
a的地址所指向的值 被 c 语言直接当成了 a 的值 。
b的地址 被 c 语言当成了 b 的值,因此,我们也将 b 称之为指针。
接下来我们对变量进行赋值并输出
#include <stdio.h>
#include <stdlib.h>
void main()
{
int a = 114514;
int b[10] = {114514,1919};
printf("%d\n" , a);
printf("%d\n" , b);
}编译运行的结果如下,我们可以发现第二行的地址貌似有点怪嗷,我们的地址不是一般 0x7f 开头吗?
114514
469523392 以16进制表示 0x1bfc5bc0要是这么想那只能说你计算机的造纸不够高,注意看 % d 是将值以 int 类型输出,int 类型所占的长度仅为 4 字节,而地址长度在 64 位机是 8 字节, b 的地址又被当成了值,因此只能输出 该地址的低4字节
紧接着继续深入,我们知道 c 语言中的 * 处了乘号之外,还有一个功能就是解引用,也就是将地址里面的值给解出来,既然 b 作为一个地址,那么我们就可以将 b 地址所存放的值用 * 给他解出来
#include <stdio.h>
#include <stdlib.h>
void main()
{
int a = 114514;
int b[10] = {114514 , 1919};
printf("%d\n" , a);
printf("%d\n" , b);
printf("%d\n" , *b);
}输出结果
114514
-879752048
114514我们又知道 b 数组的地址是连续的,那么我们可以通过加上偏移来实现索引不同位置的值,注意解引用的优先级是比加减要高的
#include <stdio.h>
#include <stdlib.h>
void main()
{
int a = 114514;
int b[10] = {114514 , 1919};
printf("%d\n" , a);
printf("%d\n" , b);
printf("%d\n" , *b);
printf("%d\n" , *(b+1));
}输出结果
114514
289332624
114514
1919我们同样实现了取下标的效果,但是这个时候可能又有同学会发问,int 类型长度不是 4 吗?为啥 b + 1 就是 b [1] 呢 不应该是 b + 4 吗?
那么还记得我们的声明吗,b 前面的 int 也不是没有作用的,这是让 c 语言知道 ,b 是一个 int 类型的指针
接下来介绍强制转换, c 语言中的指针也有强制转换,比如我们 malloc 出来的地址默认是 void * 指针,它的粒度就是 1 字节,我们可以通过 (int *) 从而强制将其转化为 int 类型,从而让 c 语言认为他是一个 4 字节为单位的 int 类型的指针
接着我们再回到上面的问题,我们将这个 b 指针首先强制转为 void * 类型,再在这个类型上 +4 偏移,其后再强转为 int * 类型并解引用出去,不就也可以输出对应地址偏移的值吗
#include <stdio.h>
#include <stdlib.h>
void main()
{
int a = 114514;
int b[10] = {114514 , 1919};
printf("%d\n" , a);
printf("%d\n" , b);
printf("%d\n" , *b);
printf("%d\n" , *(b+1));
printf("%d\n" , *(int*)((void *)b+4) ) ;
}输出结果
114514
1692555520
114514
1919
1919另外,我们也可以得到如下等式
a = b[-1] = *b-1 = *(int *)b-1 = *(int *)((void *)b-4)
接下来介绍另一个运算符 & ,这个运算符和 * 相反,& 是取地址
#include <stdio.h>
#include <stdlib.h>
void main()
{
int a = 114514;
int b[10] = {114514 , 1919};
printf("%d\n" , a);
printf("%d\n" , b);
printf("%d\n" , *b);
printf("%d\n" , *(b+1));
printf("%d\n" , *(int*)((void *)b+4) ) ;
printf("%d\n" , &a);
printf("%d\n" , *&a);
}输出结果
114514
1006296128
114514
1919
1919
1006296124
114514可以看到最后面的两行,分别输出了 a 的地址和 a 的值,可以观察和上面的地址正好相差了 4 ,这也同时印证了 a 的长度是 4 并且 a 和 b 的地址是连续的,而最后一行 通过 & * 两个运算符的使用 a 作为一个 int 值先取地址随后解引用,就又回到了它本身
那么对 c 语言的复习先到此为止
# 把史包装成一坨能上餐桌的史
# 修复错误识别
首先解决 call 很怪的问题,因为修复其涉及到 patch 程序,所以应该放到其他优化之前
((void (__fastcall *)())((char *)&sub_1268 + 1))();上面的错误便是 IDA 对函数的错误识别,点进函数切换到汇编视图可以看到下面一大片没有被 IDA 识别到而显示出了触目惊心的红色
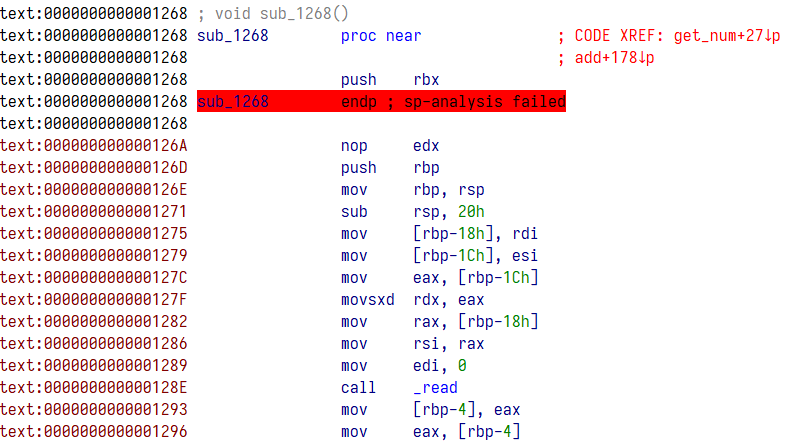
显然是上面的汇编片段出现了问题,在 push rbp 指令之前还有几条指令,在此之后的识别全部出错,所以,可以使用 IDA keypatch 插件将 push rbp 之前的指令全部 nop 掉
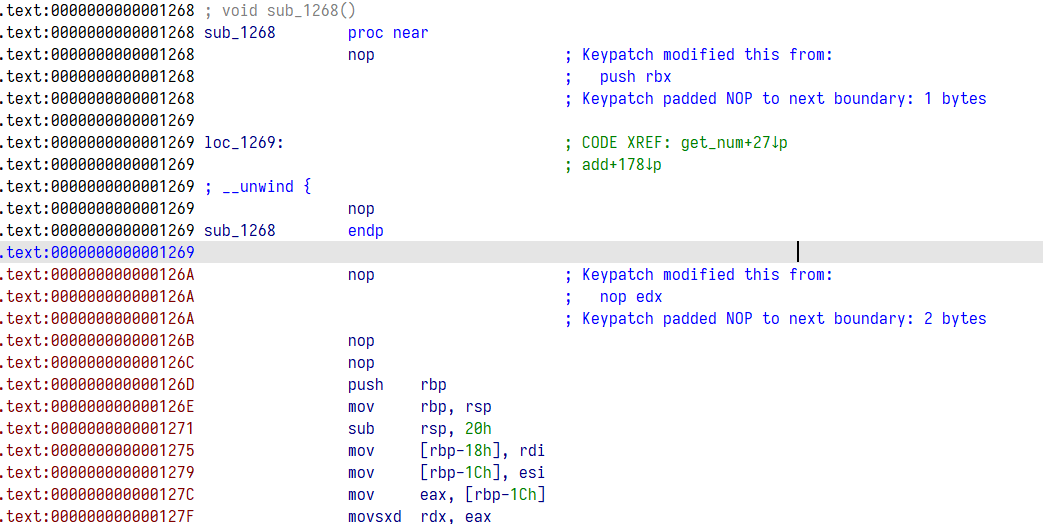
保存后再打开已经不见红了
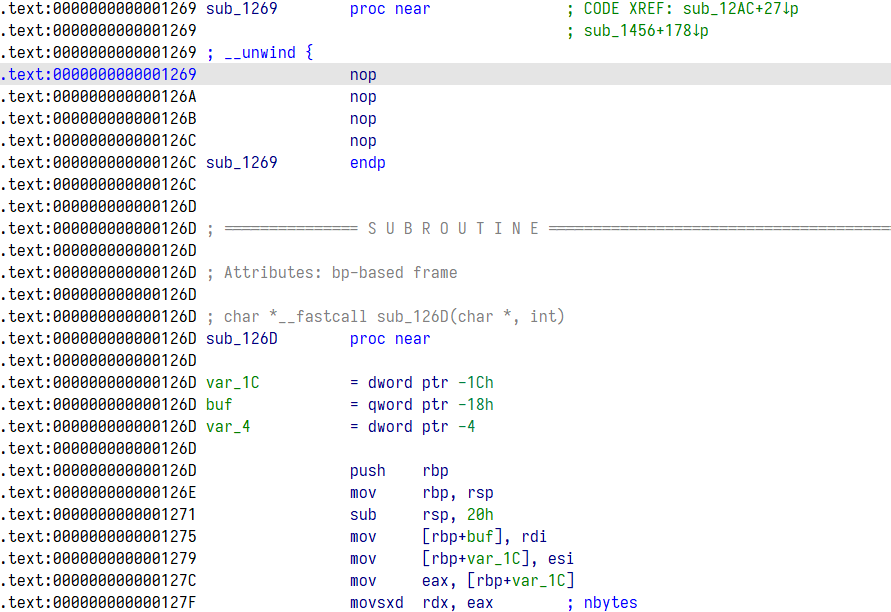
说明函数也自动被识别成功
# 修复 switch 跳转表
这算是 IDA 里的一个老坑了,反正就这么几个选项,觉得不影响的可以不去修复

同样是切到汇编视图

这里首先执行了 lea rdx, unk_2110 命令,我们点进这个地址去看,是 data 段的一条数据
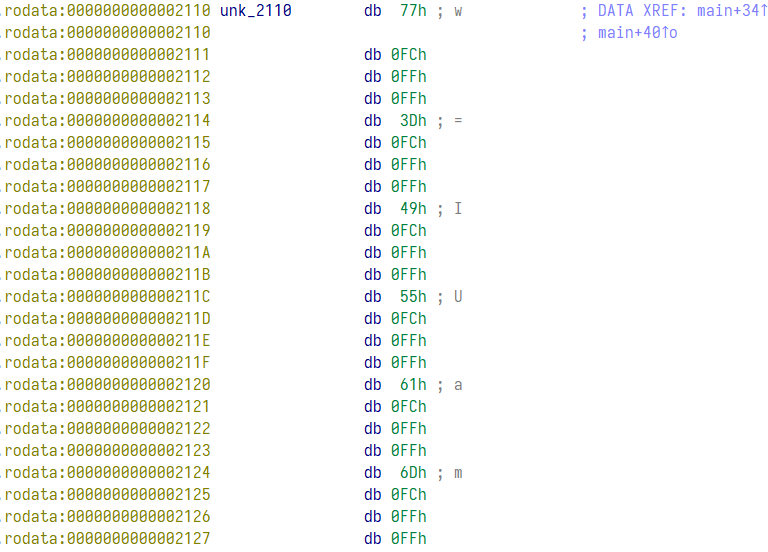
我们将上面的数据按 D 转换成 4 字节一组,那么这其实就是调转表了,可以看到其中有 6 个元素

我们再回到汇编处,这里光标选中刚刚改好的这个地址点进 Edit -> Other -> Specify switch idiom
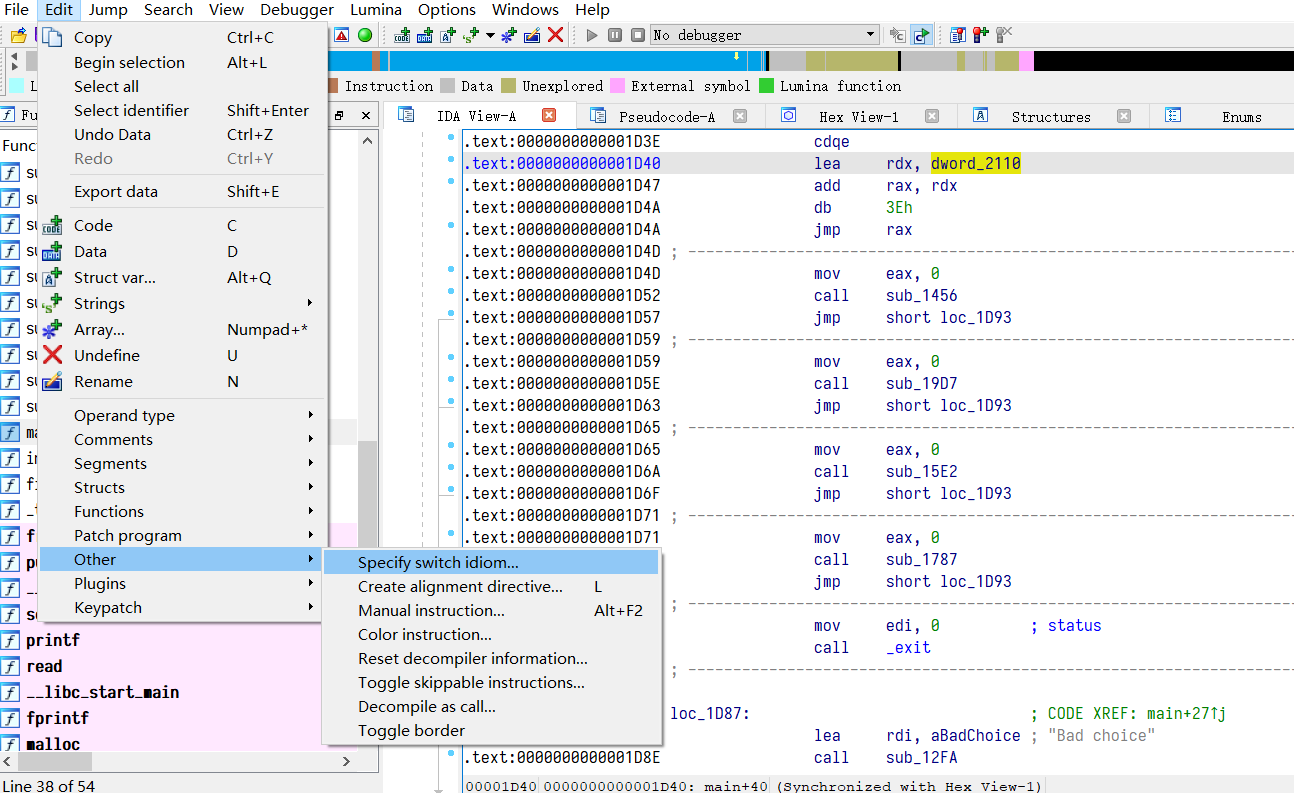
会出现如下对话框
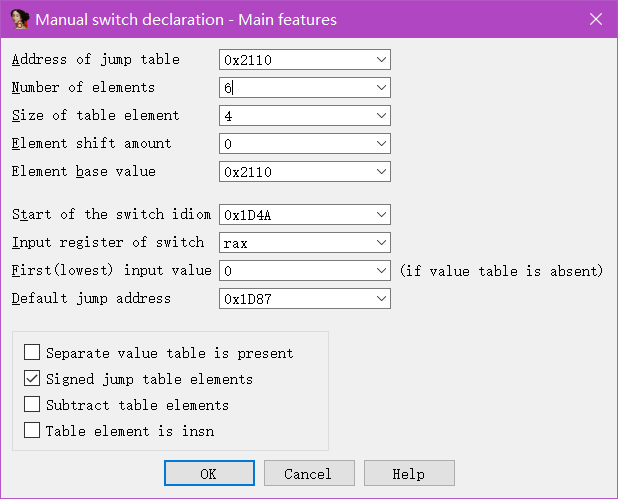
Number of elements :跳转元素个数,这个例子是 6
Size of table element :跳转表每个元素长度,这里是 4
Element base value :这里和第一个相同即可
Input register of switch :跳转到的寄存器,这里是 rax
Default jump address :默认跳转地址,这里可以看到下面的 “Bad choice”,或者直接点,最后一个就行
Signed jump table elements :如果上面看到的跳转表是负数则需要勾选此选项,比如之前看到的数据是 0xff 开头
或者按照大佬的一图流来也可以
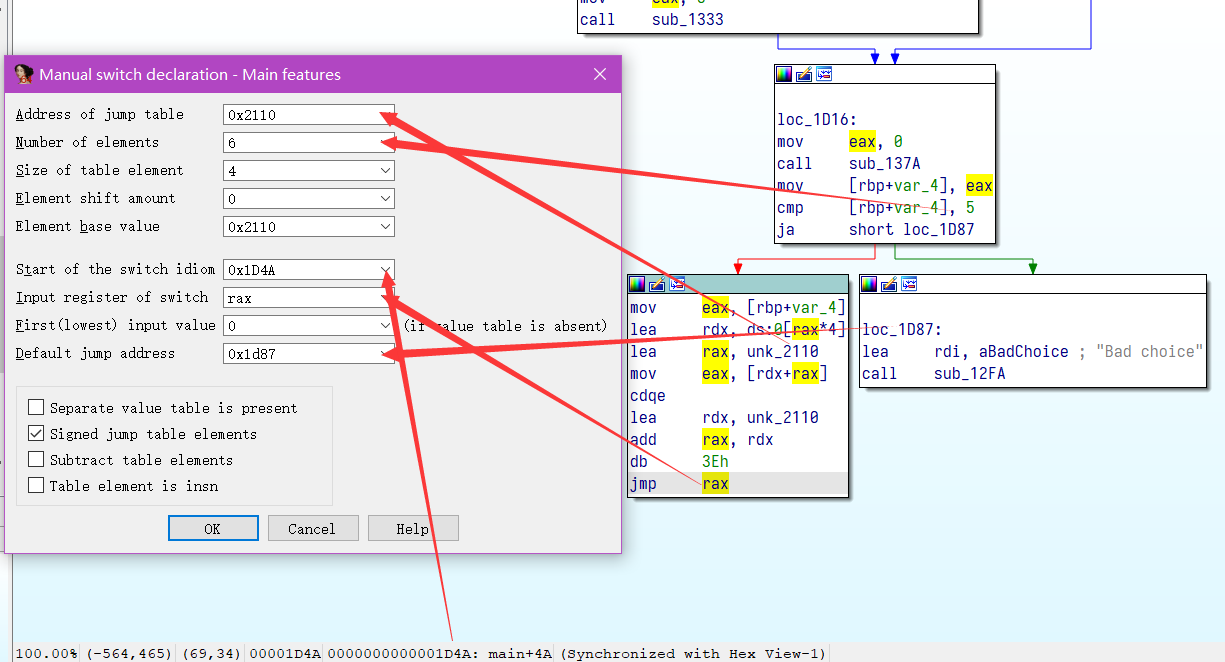
IDA 修复跳表_huzai9527 的博客 - CSDN 博客_ida switch 修复
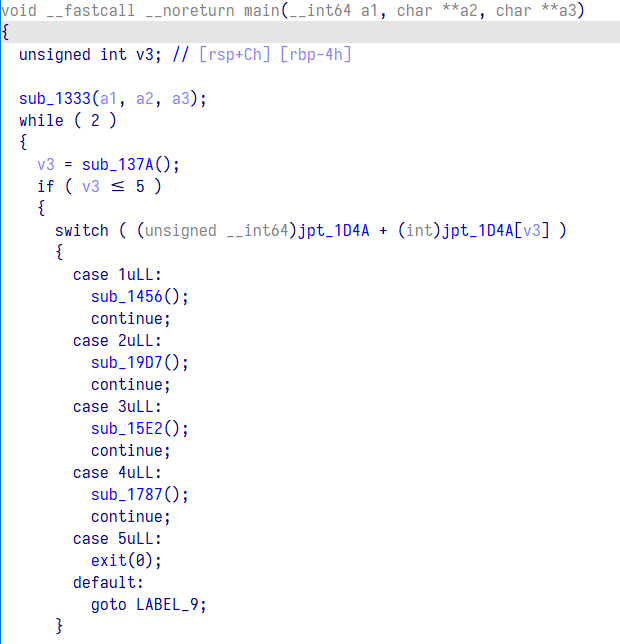
这个时候在打开 main 可以看到已经修复了
# 重命名函数和变量
我们看到的函数,变量名全是将符号表给拿掉的,我们可以通过自己的理解和命名习惯对其重命名
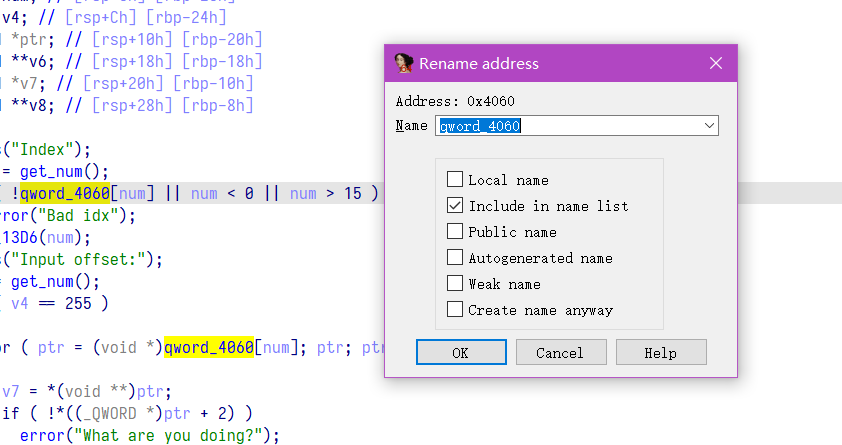
ida 快捷键 n , 在变量名或者函数名处按 n 便可以对函数进行重命名
以 add 函数为例,初步更改变量名后
int add()
{
int i; // [rsp+0h] [rbp-10h]
int choice; // [rsp+4h] [rbp-Ch]
void *buf; // [rsp+8h] [rbp-8h]
for ( i = 0; i <= 15 && *((_QWORD *)&ptr_list + i); ++i )
;
if ( i > 15 )
error("Too many link list");
puts("Size:");
choice = get_num();
if ( choice > 0x70 || choice < 0 )
error("wrong size!");
buf = malloc(choice);
*((_QWORD *)&ptr_list + i) = malloc(0x18uLL);
*(_DWORD *)(*((_QWORD *)&ptr_list + i) + 8LL) = choice;
*(_QWORD *)(*((_QWORD *)&ptr_list + i) + 16LL) = buf;
**((_QWORD **)&ptr_list + i) = 0LL;
count[i] = 1;
puts("Content:");
your_read();
return puts("Success");
}可以看到如上的代码可读性好了一些些了,按照自己的理解继续命名其他函数
# 修复强制转换
观察到上面代码中存在着很多这种扎眼的代码
*((_QWORD *)&ptr_list + i)按照我们回顾的 c 语言知识,这里看看 ptr_list 的变量类型为 _QWORD ,它并非一个常见的类型,不过从名字可以看出它就是一个 4 字 也就是 8 字节 长度的变量,首先将其取地址,随后转化为 _QWORD 指针,之后加上偏移,再解引用
注意这里别被他绕进去,先取地址再转化为指针,这个时候已经变成地址了,再解引用就又回到了那个值本身,只不过加上了偏移,因此,这不就是之前所说道的数组吗?
ida 快捷键 y , 在变量名或者函数名处按 y 便可以对函数进行类型修改
将其修改为长度为 16 的数组后,代码如下,更像人写的了
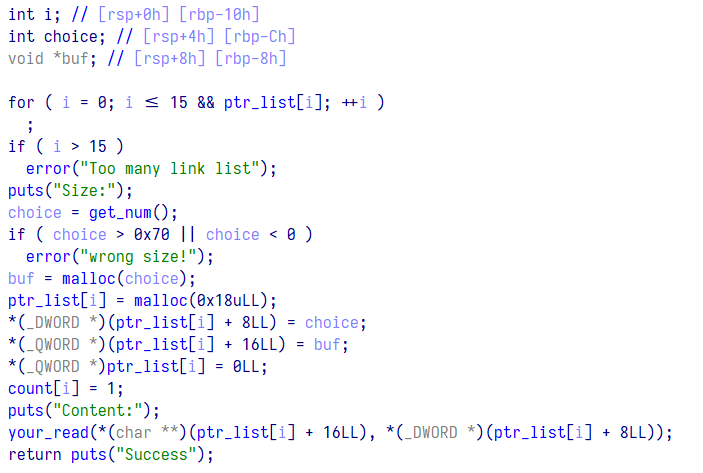
我们再思考一下,malloc 返回的是一个指针,因此用来接收它的数组也是一个指针数组,那么将其修改为指针数组
可以看到,上面对应偏移存放着不同的值,那么不用怀疑,这个指针应该对应着某种结构体,在隔壁 structues 使用 insert 新插入一个结构体,注意到上面 malloc 大小为 0x18,新建如下数组
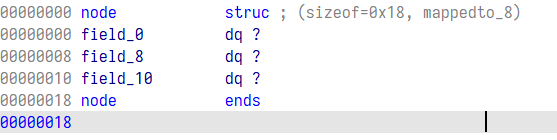
那么接下来就可以将其修改为我们新建结构体的变量类型了

出现了结构体指针的标志性 -> 符
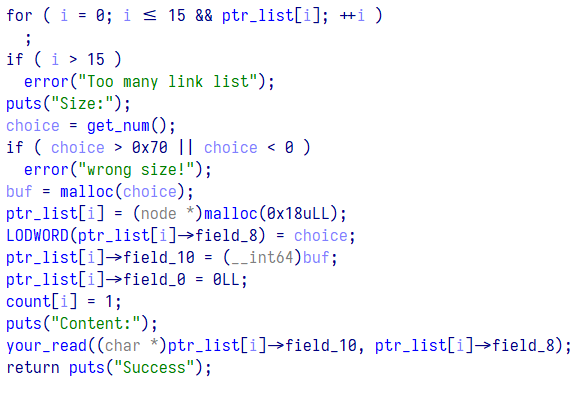
同时也发现了 LODWORD 这个操作符,出现这个的原因是结构体部分元素粒度不够细,将对应元素拆分成长度更小的元素就行,如下图,按 d 将一个 qd 拆分成两个 dd
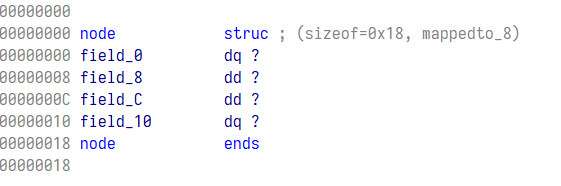
再回来已经非常接近人类写的代码了
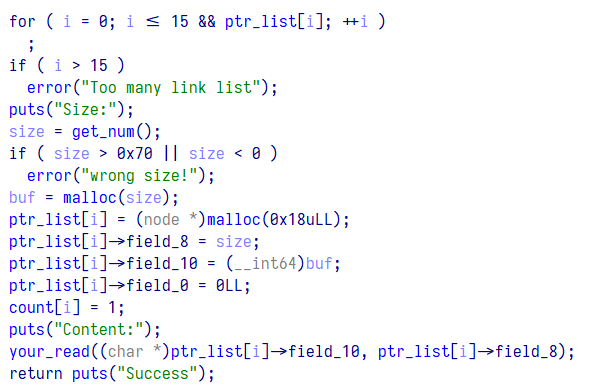
再重新重命名一下自定义结构体的各个元素
int add()
{
int i; // [rsp+0h] [rbp-10h]
int size; // [rsp+4h] [rbp-Ch]
char *buf; // [rsp+8h] [rbp-8h]
for ( i = 0; i <= 15 && ptr_list[i]; ++i )
;
if ( i > 15 )
error("Too many link list");
puts("Size:");
size = get_num();
if ( size > 0x70 || size < 0 )
error("wrong size!");
buf = (char *)malloc(size);
ptr_list[i] = (node *)malloc(0x18uLL);
ptr_list[i]->size = size;
ptr_list[i]->data = buf;
ptr_list[i]->field_0 = 0LL;
count[i] = 1;
puts("Content:");
your_read(ptr_list[i]->data, ptr_list[i]->size);
return puts("Success");
}可以看到这段代码贴进代码块已经没有什么违和感了,但该结构体还有一个疑点,我们可以进入其他函数继续分析
int link()
{
int i; // [rsp+Ch] [rbp-14h]
int idx1; // [rsp+10h] [rbp-10h]
int idx2; // [rsp+14h] [rbp-Ch]
node *ptr; // [rsp+18h] [rbp-8h]
puts("link from:");
idx1 = get_num();
if ( !ptr_list[idx1] || idx1 < 0 || idx1 > 15 )
error("Bad node");
puts("link to:");
idx2 = get_num();
if ( !ptr_list[idx2] || idx2 < 0 || idx2 > 15 )
error("Bad node");
ptr = ptr_list[idx1];
for ( i = 1; i < count[idx1]; ++i )
ptr = (node *)ptr->field_0;
ptr->field_0 = (__int64)ptr_list[idx2];
count[idx1] += count[idx2];
count[idx2] = 0;
ptr_list[idx2] = 0LL;
return puts("Success!");
}函数逻辑比较简单,看到这里,也已经知道这个 field_0 就相当于节点的 next 指针了,指向了下一个节点,因此这个元素的类型是 我们创造的结构体指针类型 ,元素名无所谓,就叫他 next 吧,改名并修改 类型

至此,本题的数据结构以及逻辑全部弄清楚了,接着可以跟随自己的习惯优化代码
# 高质量代码鉴赏环节
题目名 ez_linklist
# main
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
unsigned int choice; // [rsp+Ch] [rbp-4h]
setvbuf();
while ( 2 )
{
choice = menu();
if ( choice <= 5 )
{
switch ( (unsigned __int64)table + (int)table[choice] )
{
case 1uLL:
add();
continue;
case 2uLL:
delete();
continue;
case 3uLL:
link();
continue;
case 4uLL:
unlink();
continue;
case 5uLL:
exit(0);
default:
goto LABEL_9;
}
}
break;
}
LABEL_9:
error("Bad choice");
}# add
int add()
{
int i; // [rsp+0h] [rbp-10h]
int size; // [rsp+4h] [rbp-Ch]
char *buf; // [rsp+8h] [rbp-8h]
for ( i = 0; i <= 15 && ptr_list[i]; ++i )
;
if ( i > 15 )
error("Too many link list");
puts("Size:");
size = get_num();
if ( size > 0x70 || size < 0 )
error("wrong size!");
buf = (char *)malloc(size);
ptr_list[i] = (node *)malloc(0x18uLL);
ptr_list[i]->size = size;
ptr_list[i]->data = buf;
ptr_list[i]->next = 0LL;
count[i] = 1;
puts("Content:");
your_read(ptr_list[i]->data, ptr_list[i]->size);
return puts("Success");
}# link
int link()
{
int i; // [rsp+Ch] [rbp-14h]
int idx1; // [rsp+10h] [rbp-10h]
int idx2; // [rsp+14h] [rbp-Ch]
node *ptr; // [rsp+18h] [rbp-8h]
puts("link from:");
idx1 = get_num();
if ( !ptr_list[idx1] || idx1 < 0 || idx1 > 15 )
error("Bad node");
puts("link to:");
idx2 = get_num();
if ( !ptr_list[idx2] || idx2 < 0 || idx2 > 15 )
error("Bad node");
ptr = ptr_list[idx1];
for ( i = 1; i < count[idx1]; ++i )
ptr = ptr->next;
ptr->next = ptr_list[idx2];
count[idx1] += count[idx2];
count[idx2] = 0;
ptr_list[idx2] = 0LL;
return puts("Success!");
}# unlink
int unlink()
{
int i; // [rsp+8h] [rbp-18h]
int j; // [rsp+Ch] [rbp-14h]
int idx; // [rsp+10h] [rbp-10h]
int offset; // [rsp+14h] [rbp-Ch]
node *ptr; // [rsp+18h] [rbp-8h]
for ( i = 0; i <= 15 && ptr_list[i]; ++i )
;
if ( i > 15 )
error("Too many link list");
puts("Index:");
idx = get_num();
if ( !ptr_list[idx] || idx < 0 || idx > 15 )
error("Bad idx");
if ( count[idx] == 1 )
error("This list has only one node.");
check(idx);
puts("Input offset:");
offset = get_num();
if ( offset >= count[idx] || offset < 0 )
error("Bad offset");
if ( offset )
{
ptr = ptr_list[idx];
for ( j = 0; j < offset - 1; ++j )
ptr = ptr->next;
ptr_list[i] = ptr->next;
ptr->next = ptr->next->next;
}
else
{
ptr_list[i] = ptr_list[idx];
ptr_list[idx] = ptr_list[idx]->next;
}
--count[idx];
count[i] = 1;
return puts("Success");
}# delete
int delete()
{
_DWORD *res; // rax
int i; // [rsp+4h] [rbp-2Ch]
int idx; // [rsp+8h] [rbp-28h]
int offset; // [rsp+Ch] [rbp-24h]
node *ptr; // [rsp+10h] [rbp-20h]
node *p; // [rsp+18h] [rbp-18h]
node *next; // [rsp+20h] [rbp-10h]
node *buf; // [rsp+28h] [rbp-8h]
puts("Index");
idx = get_num();
if ( !ptr_list[idx] || idx < 0 || idx > 15 )
error("Bad idx");
check(idx);
puts("Input offset:");
offset = get_num();
if ( offset == 0xFF )
{
for ( ptr = ptr_list[idx]; ptr; ptr = next )
{
next = ptr->next;
if ( !ptr->data )
error("What are you doing?");
free(ptr->data);
ptr->size = 0;
ptr->next = 0LL;
ptr->data = 0LL;
free(ptr);
}
ptr_list[idx] = 0LL;
res = count;
count[idx] = 0;
}
else
{
if ( offset >= count[idx] || offset < 0 )
error("Bad offset");
p = ptr_list[idx];
if ( offset )
{
for ( i = 0; i < offset - 1; ++i )
p = p->next;
buf = p->next;
p->next = p->next->next;
if ( !buf->data )
error("What are you doing?");
free(buf->data);
free(buf);
}
else
{
ptr_list[idx] = ptr_list[idx]->next;
if ( !p->data )
error("What are you doing?");
free(p->data);
p->next = 0LL;
p->size = 0;
p->data = 0LL;
free(p);
}
if ( !--count[idx] )
ptr_list[idx] = 0LL;
LODWORD(res) = puts("Success");
}
return (int)res;
}各个模块的可读性非常好(喜),可不要告诉我这样了还找不到洞(
感兴趣的同学可以自己试着找一下洞,那么本期教你耍 IDA 就到此为止
本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。